
Hello Learners…
Welcome to the blog…
Topic: MPT-30B: An Introduction to the Most Powerful Open-Source LLM
Table of Contents
- Introduction
- MPT-30B: An Introduction to the Most Powerful Open-Source LLM
- What Makes MPT-30B Stand Out?
- MPT-30B serves as the foundation for two exceptional models:
- MPT-30B-Instruct
- MPT-30B-Chat
- How to Use MPT-30B Model?
- Training Data and Configuration
- Limitations and Biases
- Summary
- References
Introduction
In this article, we discuss MPT-30B: An Introduction to the Most Powerful Open-Source LLM.
MPT-30B, the groundbreaking open-source Language Model (LLM) that is redefining the boundaries of AI-driven language processing. we will see the remarkable capabilities of MPT-30B and explore how it has emerged as a game-changer in the field.
MPT-30B: An Introduction to the Most Powerful Open-Source LLM
What Makes MPT-30B Stand Out?
MPT-30B is a decoder-style transformer, pre-trained from scratch on an impressive 1T tokens of English text and code. This model features several unique attributes that set it apart from other Language Models (LLMs):
- Extended Context Window:
- MPT-30B offers an 8k token context window, allowing it to handle longer inputs effectively. This window can be further extended through finetuning, utilizing MPT-7B-StoryWriter.
- Context-Length Extrapolation:
- MPT-30B leverages ALiBi to support extrapolation of context length, enabling seamless processing of extremely long inputs
- Efficient Training and Inference:
- With FlashAttention, MPT-30B ensures fast training and inference, resulting in improved performance. It also benefits from NVIDIA’s FasterTransformer, enabling efficient deployment
- Strong Coding Abilities:
- MPT-30B excels in coding tasks, thanks to its robust pretraining mix and extensive training in English text and code
MPT-30B serves as the foundation for two exceptional models:
MPT-30B-Instruct
This model specializes in short-form instruction following. It has been meticulously crafted by finetuning MPT-30B on curated datasets, ensuring exceptional performance
MPT-30B-Chat
A chatbot-like model designed for dialogue generation. By training MPT-30B on datasets like ShareGPT-Vicuna, Camel-AI, GPTeacher, Guanaco, and Baize, and generated datasets, it delivers impressive chat capabilities.
Here we can see how it is useful and how we can use it for our project or research purpose.
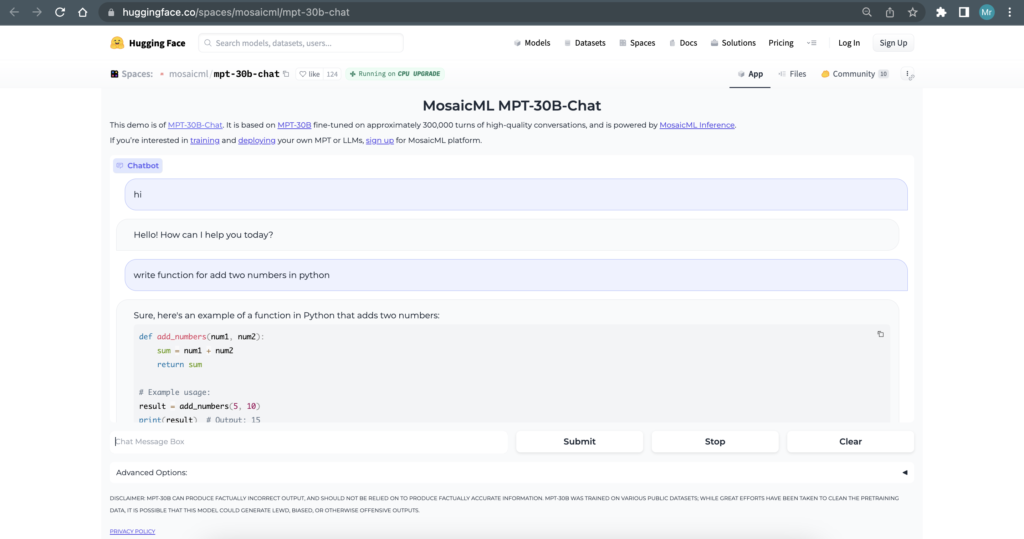
How to Use MPT-30B Model?
https://huggingface.co/mosaicml/mpt-30b-chat
import transformers
model = transformers.AutoModelForCausalLM.from_pretrained(
'mosaicml/mpt-30b-chat',
trust_remote_code=True
)Training Data and Configuration
MPT-30B is trained on an extensive mix of data sources, totaling 1T tokens. The model underwent three training stages, using a combination of A100-40GB and H100-80GB GPUs. The training process utilized the MosaicML Platform, with shared data parallelism and the LION optimizer.
Limitations and Biases
MPT-30B offers exceptional capabilities, but also we have to know its limitations. This model is not intended for deployment without finetuning and should not be solely relied upon for producing factually accurate information.
Summary
MPT-30B stands as a shining example of the incredible progress being made in the field of open-source LLMs. Its unveiling marks a new era of possibilities, where language processing reaches new heights and inspires further innovation in the field of artificial intelligence.
Also, Read