
Hello Learners…
Welcome to the blog…
Table Of Contents
- Introduction
- Why Distil-Whisper?
- Distil-Whisper: A New Speech To Text Model By HuggingFace
- What’s the difference Between Distil-Whisper and OpenAI’s Whisper Model?
- How Distil-Whisper Perform Well?
- Why use Distil-Whisper?
- Summary
- References
Introduction
In this post, we discuss about Distil-Whisper: A New Speech-To-Text Model By HuggingFace.
Why Distil-Whisper?
OpenAI’s Whisper yields astonishing accuracy for most audio, but it’s too slow and expensive for most production use cases. In addition, it has a tendency to hallucinate.
Distil-Whisper: A New Speech To Text Model By HuggingFace
Distil-Whisper is a distilled version of Whisper that is 6 times faster, 49% smaller and performs within 1% WER on out-of-distribution evaluation sets.

What’s the difference Between Distil-Whisper and OpenAI’s Whisper Model?
- 6x faster than the original Whisper from OpenAI
- Equivalent accuracy to Whisper Large
- Distilled on 20k hrs of opensource audio data
- new architecture with a frozen encoder but reduced decoder layers
- Outperforms Whisper on long-form audio
- <1% word error rate on held-out eval sets
- To be released under an MIT license
How Distil-Whisper Perform Well?
Encoding takes O(1) passes while decoding takes O(N) => Reducing decoder layers is N time more effective.
They keep the whole encoder, but only 2 decoder layers.
The encoder is frozen during distillation to ensure Whisper’s robustness to noise is kept.
To make sure Distil-Whisper does not inherit hallucinations, they filtered out all data samples below a certain WER threshold. By doing so, they are able to reduce hallucinations and actually beat the teacher on long-form audio evaluation.
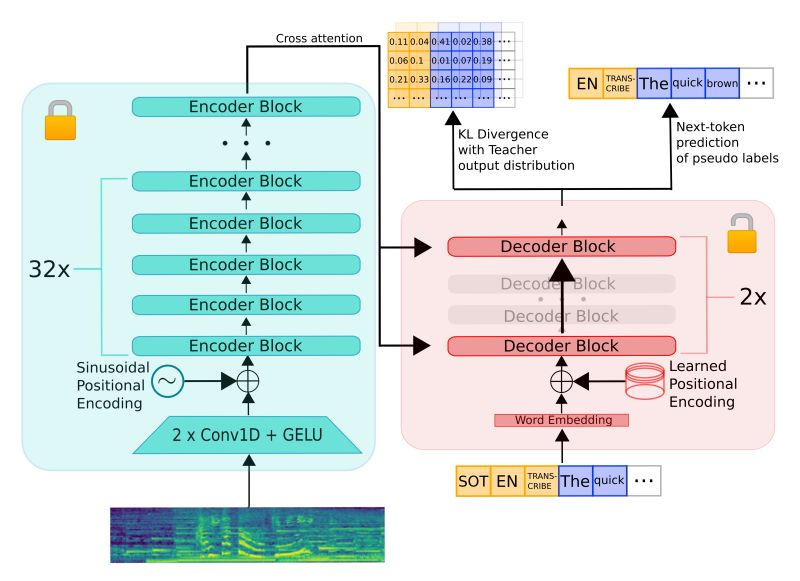
Distil-Whisper is trained on a knowledge distillation objective. Specifically, it is trained to minimize the KL divergence between the distilled model and the Whisper model, as well as the cross-entropy loss on pseudo-labeled audio data.
they train Distil-Whisper on a total of 22k hours of pseudo-labeled audio data, spanning 10 domains with over 18k speakers
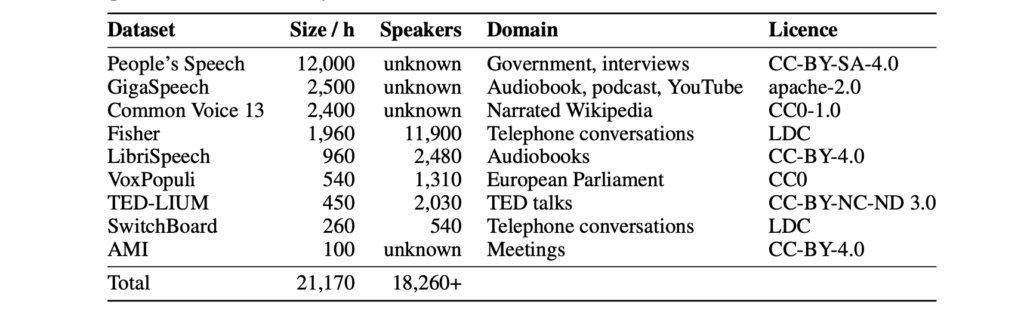
This diverse audio dataset is paramount to ensuring the robustness of Distil-Whisper to different datasets and domains.
In addition, They use a WER filter to discard pseudo-labels where Whisper mis-transcribes or hallucinates. This greatly improves the WER performance of the downstream distilled model.
GitHub URL:
Why use Distil-Whisper?
Distil-Whisper is designed to be a drop-in replacement for Whisper on English ASR. Here are 4 reasons for making the switch to Distil-Whisper:
1. Faster inference:
6 times faster inference speed, while performing to within 1% WER of Whisper on out-of-distribution audio
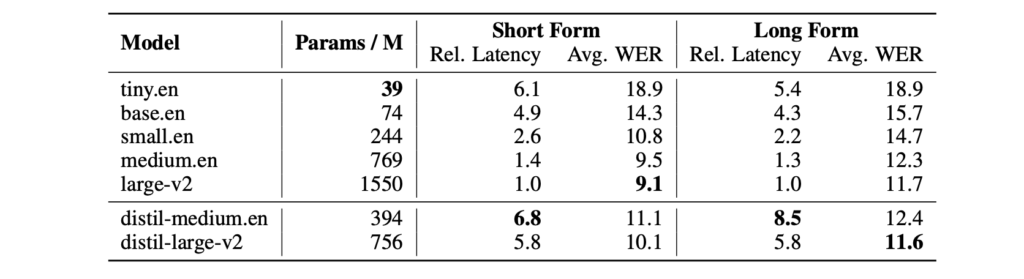
2. Robustness to noise
demonstrated by strong WER performance at low signal-to-noise ratios

3. Robustness to hallucinations
quantified by 1.3 times fewer repeated 5-gram word duplicates (5-Dup.) and a 2.1% lower insertion error rate (IER) than Whisper
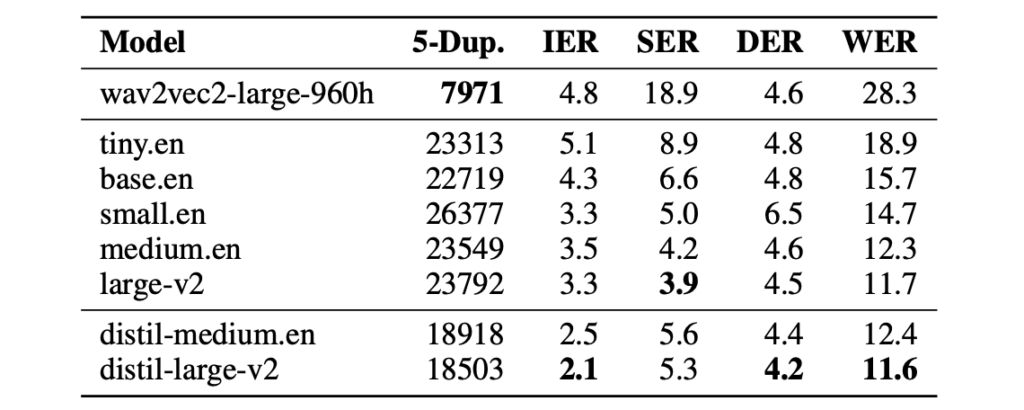
4. Designed for speculative decoding
Distil-Whisper can be used as an assistant model to Whisper, giving 2 times faster inference speed while mathematically ensuring the same outputs as the Whisper model
Summary
In conclusion, Distil-Whisper, the latest addition to Hugging Face’s remarkable lineup of language models, brings a new level of efficiency and accuracy to the world of speech-to-text conversion.
Also, you can learn more about these types of models from the below URL:
Happy Learning And Keep Learning…
Thank You…
It was great seeing how much work you put into it. Even though the design is nice and the writing is stylish, you seem to be having trouble with it. I think you should really try sending the next article. I’ll definitely be back for more of the same if you protect this hike.