
Hello Learners…
Welcome to the blog…
Table Of Contents
- Introduction
- What is CodeGemma?
- Unlocking Gemma’s Coding Journey: Meet CodeGemma
- Evaluation Report Of CodeGemma
- CodeGemma Models On HuggingFace
- Run CodeGemma Model Using Transformers
- Summary
- References
Introduction
In this post, we discuss Unlocking Gemma’s Coding Journey: Meet CodeGemma.
CodeGemma serves as a tool for developers and businesses, offering features such as code completion, generation, and chat functionalities.
What is CodeGemma?
CodeGemma is a family of open-access versions of Gemma specialized in code, and we’re excited to collaborate with Google on its release to make it as accessible as possible.
Unlocking Gemma’s Coding Journey: Meet CodeGemma
CodeGemma is a family of code-specialist LLM models by Google, based on the pre-trained 2B and 7B Gemma checkpoints.
We can further trained CodeGemma on an additional 500 billion tokens of primarily English language data, mathematics, and code to enhance logical and mathematical reasoning. They are suitable for code completion and generation.
We exclusively trained CodeGemma 2B on Code Infilling for rapid code completion and generation, particularly in environments where latency and/or privacy are paramount.
The CodeGemma 7B training mix comprises 80% code infilling data and natural language. It enables usage for code completion, as well as understanding and generation of both code and language.
We fine-tuned CodeGemma 7B Instruct for instruction following on top of CodeGemma 7B. This model is intended for conversational use, particularly regarding topics related to code, programming, or mathematical reasoning.
All the models have the same 8K token context size as their predecessors.
CodeGemma comes in three flavors:
- A 2B base model specialized in infilling and open-ended generation.
- A 7B base model trained with both code infilling and natural language.
- A 7B instruct model a user can chat with about code.
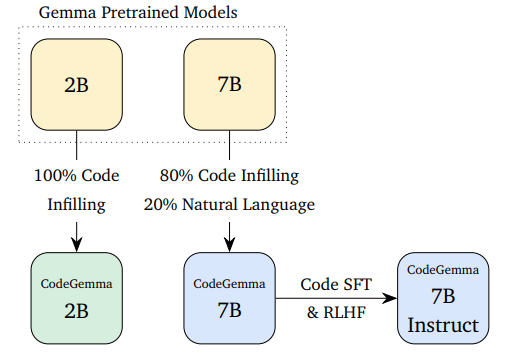
This image is from https://goo.gle/codegemma
Evaluation Report Of CodeGemma
Here is a table from the original report with a breakdown per language.
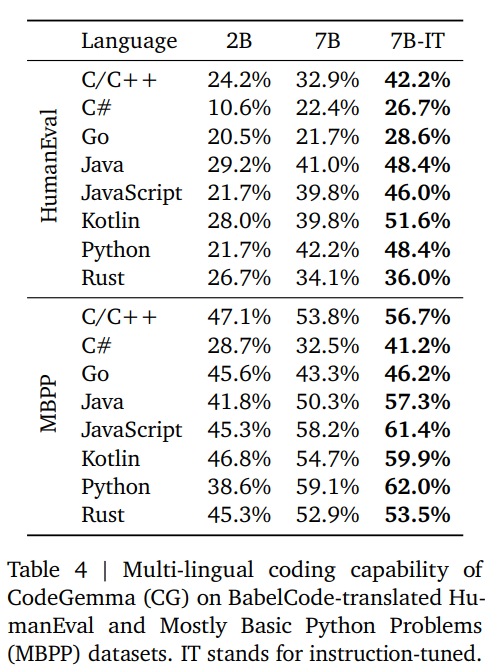
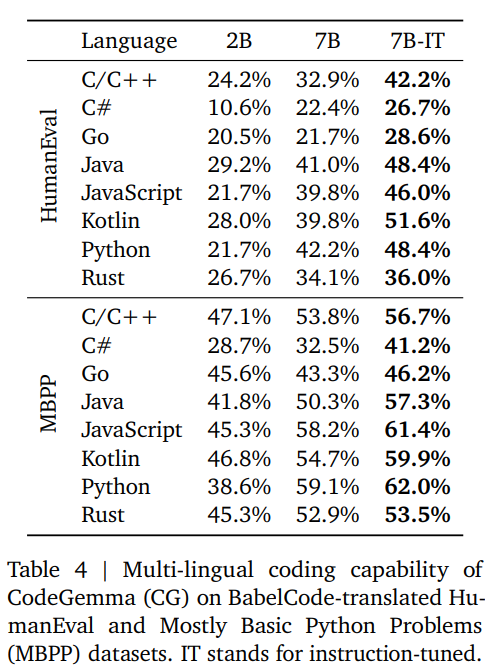{kind=link}
CodeGemma Models On HuggingFace :
Run CodeGemma Model Using Transformers
With Transformers release 4.39, we can use CodeGemma and leverage all the tools within the Hugging Face ecosystem, such as:
- training and inference scripts and examples
- safe file format (
safetensors) - integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning), and Flash Attention 2
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
Like the Gemma models, CodeGemma is compatible with torch.compile() for an important inference speedup.
Bonus: We made a Colab notebook for you to try out the model at the touch of a button here.
To use CodeGemma with transformers, make sure to use the latest release:
pip install --upgrade transformersThe following snippet shows how to use codegemma-2b for code completion with transformers.
It requires about 6 GB of RAM using float16 precision, making it perfectly suitable for consumer GPUs and on-device applications.
from transformers import GemmaTokenizer, AutoModelForCausalLM
import torch
model_id = "google/codegemma-2b"
tokenizer = GemmaTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda:0")
prompt = '''\
<|fim_prefix|>import datetime
def calculate_age(birth_year):
"""Calculates a person's age based on their birth year."""
current_year = datetime.date.today().year
<|fim_suffix|>
return age<|fim_middle|>\
'''
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
prompt_len = inputs["input_ids"].shape[-1]
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0][prompt_len:]))Observe that the <|fim_suffix|> token appears in the position where the cursor would be placed in an editor, marking the position for the generation. <|fim_prefix|> provides the context that precedes the cursor, and the remaining until <|fim_middle|> is additional context after the cursor. Either of them can be empty if the cursor is located at the beginning or end of the file.
The previous code may return something like the following:
age = current_year - birth_year<|file_separator|>test_calculate_age.py
<|fim_suffix|>
assert calculate_age(1990) == 33
assert calculate_age(1980) == 43
assert calculate_age(1970) == 53
assert calculate_age(1960) == 63
assert calculate_age(1950) == 73Note the extra content after the correct completion. This is particularly the case for CodeGemma 7B, which is more verbose and tends to provide additional code or comments after completion. We must ignore everything that appears after the FIM tokens or the EOS token for code infilling. We can stop generation early with transformers by providing a list of terminators to the generate function, like this:
FIM_PREFIX = '<|fim_prefix|>'
FIM_SUFFIX = '<|fim_suffix|>'
FIM_MIDDLE = '<|fim_middle|>'
FIM_FILE_SEPARATOR = '<|file_separator|>'
terminators = tokenizer.convert_tokens_to_ids(
[FIM_PREFIX, FIM_MIDDLE, FIM_SUFFIX, FIM_FILE_SEPARATOR]
)
terminators += [tokenizer.eos_token_id]
outputs = model.generate(
**inputs,
max_new_tokens=100,
eos_token_id=terminators,
)In this case, generation will stop as soon as the first delimiter is found:
age = current_year - birth_year<|file_separator|>Summary
Also you can refer this,
Stumbling upon this website was such a delightful find. The layout is clean and inviting, making it a pleasure to explore the terrific content. I’m incredibly impressed by the level of effort and passion that clearly goes into maintaining such a valuable online space.