
Hello Learners…
Welcome To My Blog…
Table Of Contents:
- Introduction
- What is speech-to-text?
- What is OpenAI’s whisper?
- Speech-to-text using python and OpenAI’s whisper
- Summary
- References
Introduction
In this post, we create a web app for speech-to-text using python and OpenAI’s whisper.
What is Speech-To-Text?
Speech-to-text is the conversion of voice data into text data. speech to text is widely used everywhere at this time.
What is OpenAI’s Whisper?
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.
Speech-to-text using python and OpenAI’s whisper
Here we create a simple web app for a speech-to-text using the python streamlit library and OpenAI’s whisper model.
First, we install the streamlit library using the pip command, open your terminal and enter the below command:
pip install streamlitTo record our voice we have to install the audio_recorder_streamlit library using the pip command:
pip install audio_recorder_streamlitAfter we install openai–whisper using the pip command:
pip install -U openai-whisperIt takes time based on internet speed.
After this, we have to download the pre-trained model of open-whisper, here are the models available for download which we can use based on our requirements and we simply use it.
Every Model has a different size and different hardware requirements.
Here we use base.en model. which is 145MB in size. and the model is base.en.pt which is a pytorch model.
Download it and put it in our current working directory. so we can use it.
Now we create a web app using streamlit, here is the code
Create a file app.py and paste the below code into that file.
Code:
import streamlit as st
from audio_recorder_streamlit import audio_recorder
import whisper
import os
st.title("Speech To Text")
def main():
audio_bytes = audio_recorder()
if audio_bytes:
st.audio(audio_bytes, format="audio/wav")
if os.path.isfile("myfile.wav"):
os.remove("myfile.wav")
with open('myfile.wav', mode='bx') as f:
f.write(audio_bytes)
if os.path.isfile("myfile.wav"):
model = whisper.load_model("./base.en.pt",device='cpu')
result = model.transcribe("myfile.wav")
st.write(result['text'])
os.remove("myfile.wav")
else:
st.error("please record your voice")
main()Now run the file, open the terminal, and run the below command:
streamlit run app.pyWe get an URL: http://localhost:8501/
It will automatically be redirected to our default browser also we can manually open it in our browser, we can see the below interface.
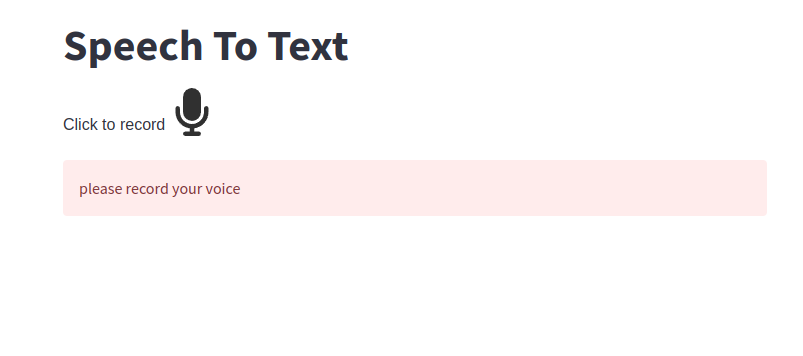
Now click the record icon it will turn into red color and start speaking it will record your voice when you want to stop click again and then it will convert your voice into text.

Here we can see our output text.
Summary
This is a simple voice-to-text web app, we can use these models for any type of speech-to-text.
Happy Learning And Keep Learning…
Thank You…
Also, you can read my other articles for learning…