
Hello Learners…
Welcome to the blog…
Table Of Contents
- Introduction
- Can we pre-train LLMs with Retrieval Augmentation?
- What is Retrieval Augmentation?
- Summary
- References
Introduction
In this post, we try to explore how Can we pre-train LLMs with Retrieval Augmentation.
What is Retrieval Augmentation?
Retrieval augmented generation (RAG) is a technique for improving the performance of large language models (LLMs) by providing them with access to external knowledge sources.
Can we pre-train LLMs with Retrieval Augmentation?
RETRO was a research by Google DeepMind, which included retrieval into the pre-training process. Now NVIDIA continues this research by scaling RETRO to 48B, where they continued pretraining a 43B GPT model on an additional 100 billion tokens using the Retrieval augmentation method by retrieving from 1.2 trillion tokens.
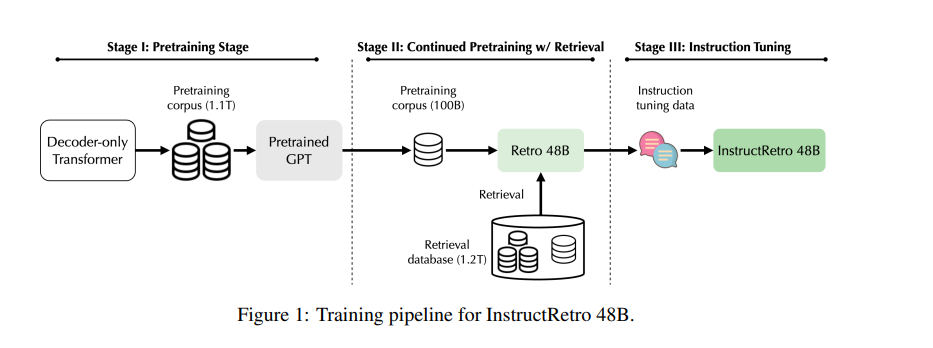
In this research, the authors explore the advantages of pretraining large language models (LLMs) with a retrieval-based approach.
They find that this approach leads to an improved way of understanding something and factual accuracy, particularly by utilizing external databases.
However, the current pretrained retrieval-augmented LLMs have limited size, such as the 7.5 billion parameters in Retro, which restricts their effectiveness in instruction tuning and zero-shot generalization.
To address this limitation, the authors introduce Retro 48B, a much larger LLM pre-trained with a retrieval method before instruction tuning.
They achieve this by continuing the pretraining of the 43B GPT model with an additional 100 billion tokens obtained through retrieval from a massive 1.2 trillion tokens.
The resulting foundation model, Retro 48B, significantly outperforms the original 43B GPT model in terms of perplexity.
After instruction tuning on Retro, a model called InstructRetro shows substantial improvements in zero-shot question answering (QA) tasks compared to the instruction-tuned GPT.
In particular, InstructRetro demonstrates an average improvement of 7% over its GPT counterpart across 8 short-form QA tasks and 10% over GPT across 4 challenging long-form QA tasks.
Interestingly, the authors discovered that they could remove the encoder from the InstructRetro architecture and directly utilize its decoder backbone while achieving similar results.
Summary
This suggests that the pretraining with retrieval significantly enhances the decoder’s ability to incorporate context for QA. Overall, the findings suggest a promising approach to obtaining an improved GPT decoder for QA through continued pretraining with retrieval before instruction tuning.
Also, you can read…
Happy Learning And Keep Learning…
Thank You…
Thank you for the auspicious writeup It in fact was a amusement account it Look advanced to more added agreeable from you By the way how could we communicate
I enjoy your website, obviously, but you should check the spelling on a number of your posts. A number of them have numerous spelling errors, which makes it difficult for me to tell the truth, but I will definitely return.