
Hello Learners…
Welcome to the blog…
Table Of Contents
- Introduction
- Count Tokens For OpenAI’s Models Using Python
- What Are The Tokens?
- How To Count Tokens For OpenAI’s Models Using Python?
- How to check the string representations of the token?
- Summary
- References
Introduction
This post discusses how we can Count Tokens For OpenAI’s Models Using Python.
Currently, everyone is using OpenAI’s Models in their businesses, and growing their business, In this post we discuss how we count the tokens and see the pricing of different OpenAI models for tokens.
Count Tokens For OpenAI’s Models Using Python
What Are The Tokens?
The token is the most used term in natural language processing (NLP), token is a unit of text that is used to represent a meaningful aspect of a sentence.
Tokens can be words, phrases, or even individual characters. The process of breaking a sentence down into tokens is called tokenization.
Splitting text strings into tokens is useful because GPT models see text in the form of tokens. Knowing how many tokens are in a text string can tell you (a) whether the string is too long for a text model to process and (b) how much an OpenAI API call costs (as usage is priced by token).
Count Tokens Using Python tiktoken
Here, we use the ‘tiktoken‘ library which is a fast and open-source tokenizer by OpenAI.
NOTE: To count tokens using tiktoken we don’t require any paid API key. It’s completely free.
First, we have to install the required libraries,
pip install tiktokenSo now we see how we can count the tokens,
First, here we use the ‘gpt-3.5-turbo‘ OpenAI model as an example, you can use any models provided by an OpenAI.
import tiktoken
encoding=tiktoken.encoding_for_model("gpt-3.5-turbo")
encoding.encode("Hello how are you?")
This is how tiktoken converts strings into integers.
def num_of_tokens_from_text(text:str,model:str)->int:
"""Return the numbers of tokens in the given text"""
encoding=tiktoken.encoding_for_model(model_name=model)
num_tokens=len(encoding.encode(text=text))
return num_tokens
num_of_tokens_from_text("hello how are you???",model='gpt-3.5-turbo')The output of the above code snippets,
#Output
5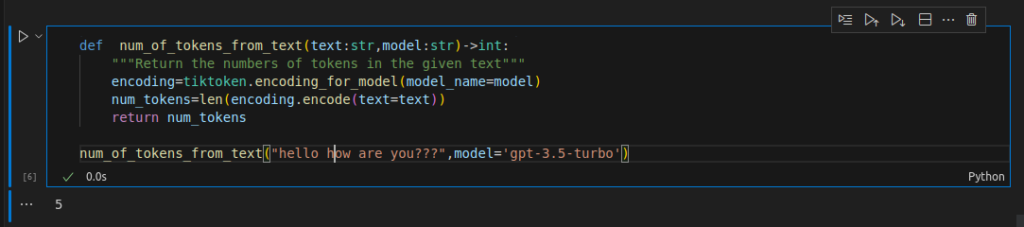
How to check the string representations of the token?
As we see above how we can count tokens but if we want to see the string representation of every token then we can decode the integer values to string.
def token_list_from_text(text:str,model:str)->list:
"""Return the numbers of tokens in the given text"""
encoding=tiktoken.encoding_for_model(model_name=model)
num_tokens=encoding.encode(text=text)
token_list=[]
for i in num_tokens:
token_value=encoding.decode_single_token_bytes(i)
token_list.append(token_value)
return token_list
token_list_from_text("hello how are you???",model='gpt-3.5-turbo')
#Output
[b'hello', b' how', b' are', b' you', b'???']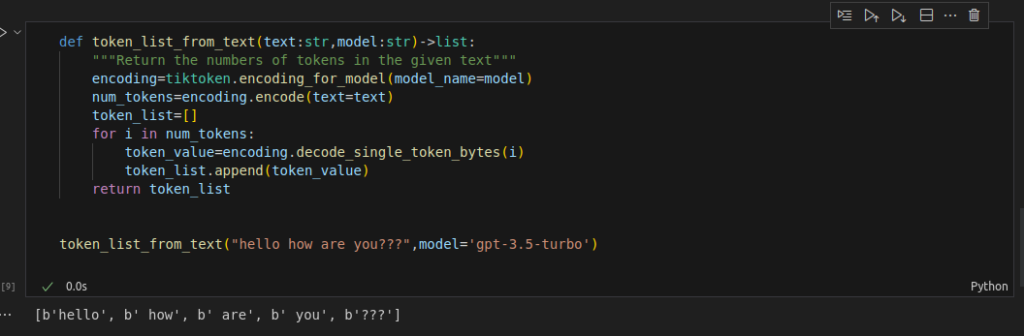
So, as we see the string representations of every token from the sentence given by us.
Keep Going…
Summary
In conclusion, counting tokens for OpenAI’s models using Python can be a useful process for various tasks.
After understanding the number of tokens in a model, we can gain insights into its complexity, performance, and resource requirements. Token counting allows us to estimate memory usage, evaluate model efficiency, and make informed decisions about deployment and optimization strategies.
Also, you can read,
Happy Learning And Keep Learning…
Thank You…