Hello Learners…
Welcome to the blog…
Table Of Contents
- Introduction
- Everything About Vector Embeddings
- What are vector embeddings?
- What are word embeddings?
- What are sentence embeddings?
- Embedding vectors in other domains
- Applications of Embeddings
- Sentence Embeddings: Crucial For RAG
- Cross Encoder for Relevance Ranking
- Summary
- References
Introduction
In this post, we discuss about Everything About Vector Embeddings.
Everything About Vector Embeddings
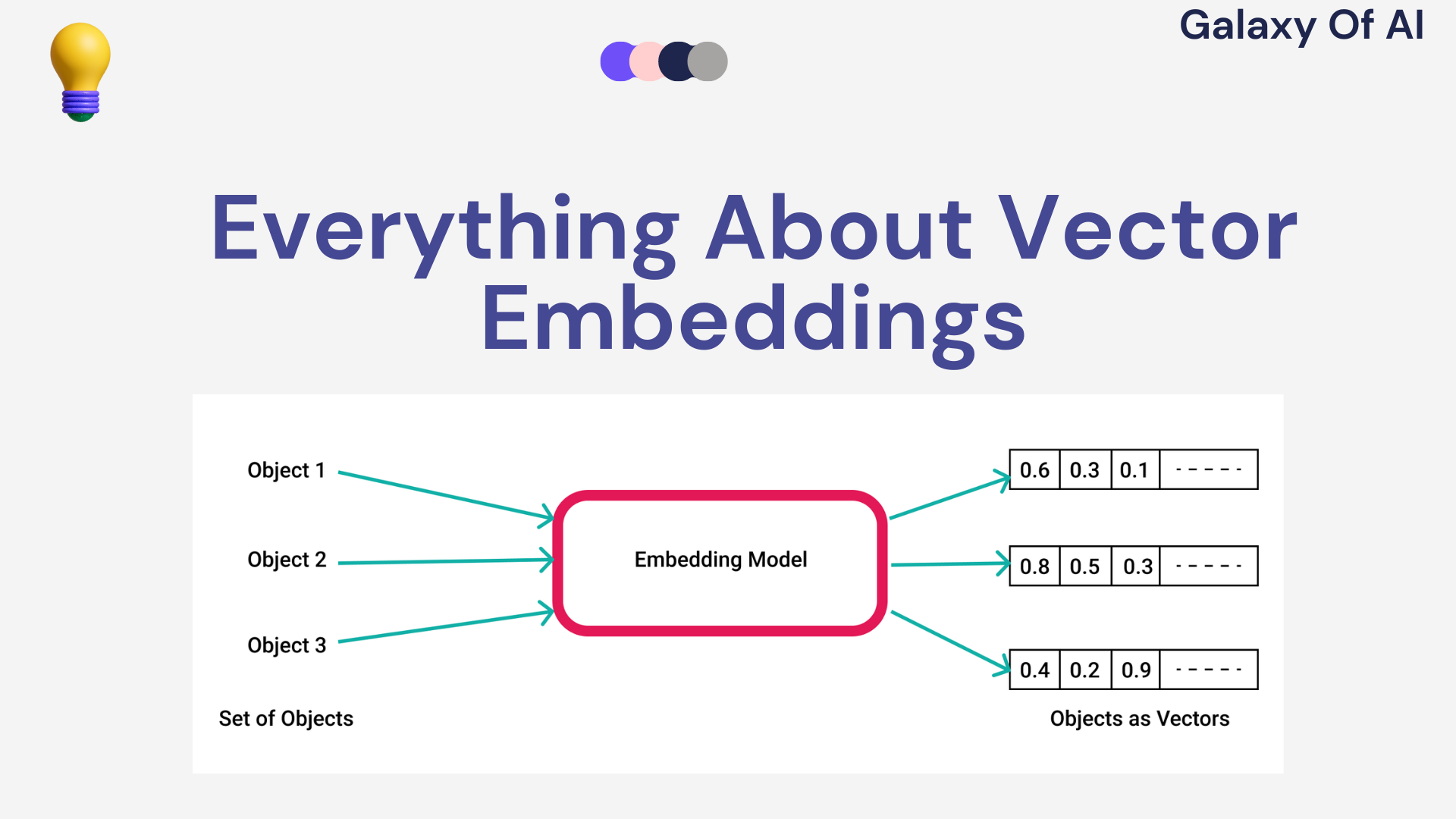
What are vector embeddings?
Vector embedding map real-world entities such as a word, a sentence or an image into vector representations, or a point in some vector space.
A key characteristic of this representation is that points in some vector space that are similar to each other in some way have a similar semantic meaning.
What are word embeddings?
Word2vec was the pioneering work on learning token or word embeddings that maintain semantic meaning, demonstrating that dense vector based representation of words can capture their semantic meaning.
The really cool thing is that these word embedding vectors behave like vectors in a vector space, and we can use algebraic equations and operations on them.
There was a very famous example showing that the closest vector to queen minus woman plus man is king.
What are sentence embeddings?
Dense vector representations of sentence that capture their semantic meaning.
It converts a sentence into a vector of numbers that represents the semantic meaning of whole sentence.
Embedding vectors in other domains
- Image Embedding:
- Translate visual content to vector form.
- Video Embedding:
- Capture the characteristic of video data, including visual appearance and temporal dynamics.
- Audio Embedding:
- Represent sound signals in a vector space.
- Graph Embedding:
- Convert nodes, edges and their features in a graph into vector space, preserving structural information.
Applications of Embeddings
- LLMs:
- Input tokens are converted into token embeddings
- Semantic Search:
- Enhance search engines by retrieving sentences with similar meanings, improving search relevance.
- RAG:
- Sentence embeddings enables efficient retrieval of relevant chunks
- Recommandations:
- Representing products in embedding space and using similarity search.
- Anomaly Detection:
- Identifies patterns in data that deviate significantly from the norm.
Sentence Embeddings: Crucial For RAG
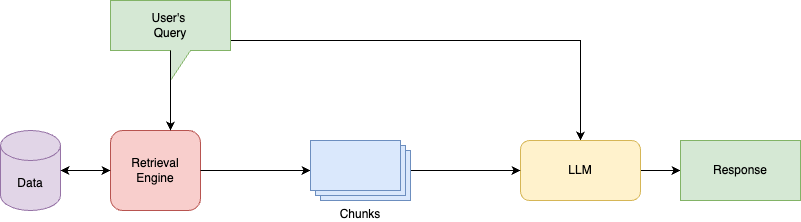
Given user’s query we rank order all possible text chunks by the relevance to the query, before sending the facts to the LLM for generating response.
So, What algorithms can we use for optimal retrieval?
Cross Encoder for Relevance Ranking
One approach for ranking text chunks by relevance is a using cross encoder.
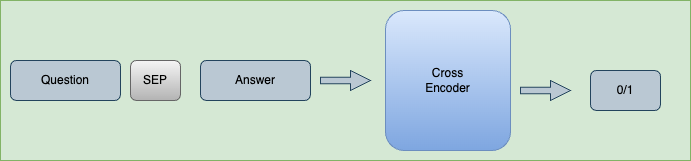
A cross encoder is a transformer based neural network model that is use as a classifier to determine the relevance.
But there is one big problem, cross encoders are very slow, and this approach requires us to run this classification operation for every text chunk in our data set. So this does not scale.
Sentence Embedding Models for Relevance Ranking
Sentence embedding models provide an alternative. This works as follow.
During indexing, we create an embedding for each text segment and store into vector database.
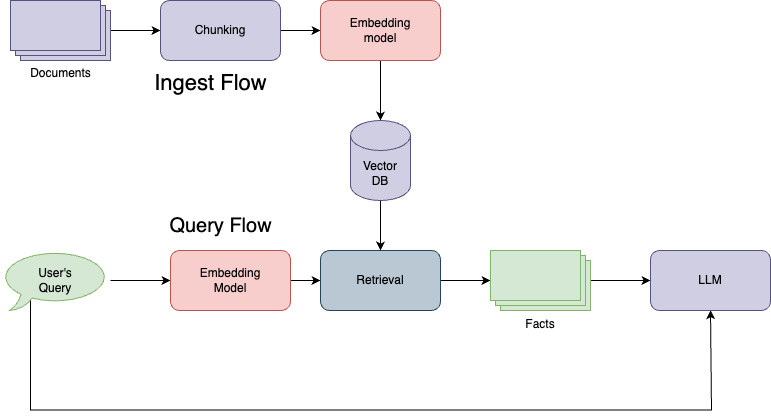
When user’s ask any query, we use similarity search to identify the best matching chunks to retrieve.
This is often less accurate than cross encoders, but it’s much faster and provide a realistic and practical implementation path.
Summary
Vector embeddings are a powerful tool for many machine learning tasks, capturing complex relationships in a way that makes them manageable for algorithms.
As the field continues to evolve, embedding techniques will likely become even more sophisticated and integral to AI applications.