
Hello Learners…
Welcome to the blog…
Topic: Kosmos-2: Grounding Multimodal Large Language Models to the World
Table Of Contents
- Introduction
- Introducing Kosmos-2: Unveiling the Next Frontier of Multimodal Large Language Models by Microsoft
- Summary
- References
Introduction
In this post, we Introduce Kosmos-2: Unveiling the Next Frontier of Multimodal Large Language Models by Microsoft.
In this era of rapidly evolving artificial intelligence, Microsoft has once again pushed the boundaries of technology by unveiling its latest creation: a groundbreaking multimodal large language model. Kosmos-2 promises to revolutionize the way we interact with machines, taking us one step closer to seamless human-machine communication.
Here we explore the capabilities, significance, and potential impact of Kosmos-2 in this exciting new chapter on language models and AI innovation. Get ready to embark on a journey into the world of Kosmos-2, where the possibilities of AI are expanded beyond what we ever thought possible.
Introducing Kosmos-2: Unveiling the Next Frontier of Multimodal Large Language Models by Microsoft
Kosmos-2: Grounding Multimodal Large Language Models (LLMs) can describe our image and generate text which is related to our input image.
You can see the demo using the below URL,
For Demo:
This is the web interface that they provide, it is created by using Gradio.
Here we upload some image and test what will be output it gives,
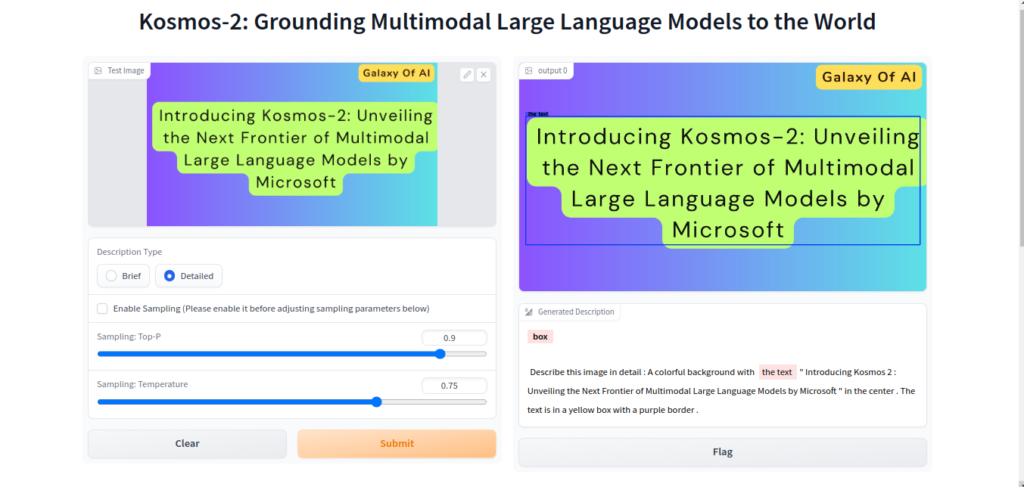
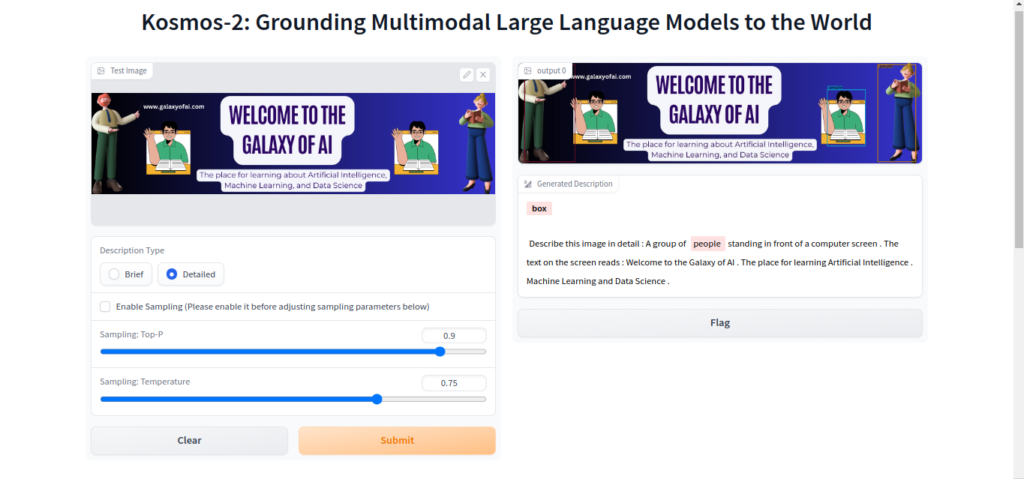
Research Paper,
Download the Research paper pdf file,
What Kosmos-2 Can Do?
Kosmos-2 enables new capabilities of perceiving object descriptions (e.g., bounding boxes) and
grounding text to the visual world.
Grounding capability can provide a more convenient and efficient human-AI interaction for vision-language tasks.
They Evaluate KOSMOS-2 on a wide range of tasks, including
- multimodal grounding, such as referring expression comprehension, and phrase grounding,
- multimodal referring, such as referring expression generation,
- perception-language tasks,
- language understanding and generation
Summary
To learn more about llms,