
Hello Learners…
Welcome to the blog…
Table Of Contents
- Introduction
- RAG and Longer Context Windows: Which Boosts Performance?
- Summary
- References
Introduction
In this post, we give some information about Retrieval meets Long Context, Large Language Models. This is a research paper that defines RAG and Longer Context Windows: Which Boosts Performance in NLP?
Extending the context window of large language models (LLMs) has become popular recently.
RAG and Longer Context Windows: Which Boosts Performance?
Extending the context window of large language models (LLMs) has become popular recently, while the solution of augmenting LLMs with retrieval has existed for years.
The natural questions are:
i) Retrieval-augmentation versus long context window, which one is better for downstream tasks? ii) Can both methods be combined to get the best of both worlds?
A new study from NVIDIA compares retrieval augmentation generation (RAG) with increasing context windows for large language models (LLMs) on long context question answering and summarization tasks.
Model Comparison
In the given research paper they answer these questions by studying both solutions using two state-of-the-art pre-trained LLMs, i.e., a proprietary 43B GPT and LLaMA2-70B.
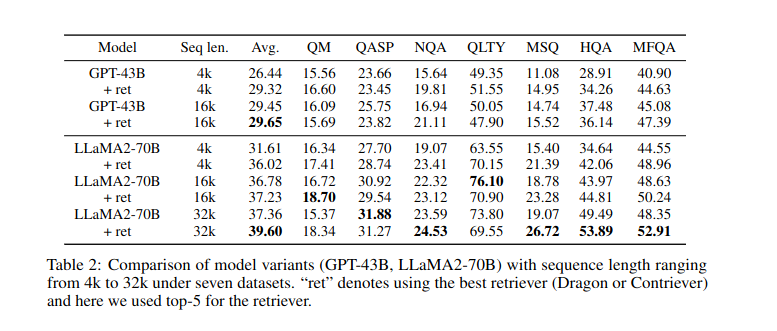
And, they find that LLM with a 4K context window using simple retrieval augmentation at generation can achieve comparable performance to finetuned LLM with a 16K context window via positional interpolation on long context tasks while taking much less computation.
More importantly, they demonstrate that retrieval can significantly improve the performance of LLMs regardless of their extended context window sizes.
Their best model, retrieval-augmented LLaMA2-70B with 32K context window, outperforms GPT-3.5-turbo-16k and Davinci003 in terms of the average score on seven long context tasks including question answering and query-based summarization.
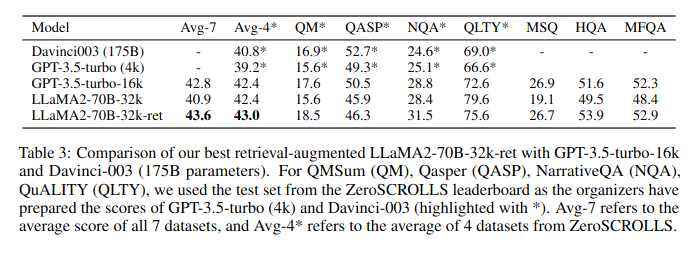
It also outperforms its non-retrieval LLaMA2-70B-32k baseline by a margin, while being much faster at generation.
Their study provides general insights on the choice of retrieval-augmentation versus long context extension of LLM for practitioners.
- Started from two LLMs, NVIDIA 43B GPT and Llama 2 70B.
- Extended context window to 16k for GPT-43B and 16K/32k for Llama using positional interpolation using the PILE dataset
- Instruction-tuned small and big context models on QA and summarization
- Used 3 different Retriever (Dragon, Contriever, OpenAI embeddings) to embed and retrieve relevant context chunks.
- Evaluated on 7 datasets – QMSum, Qasper, NarrativeQA, QuALITY, MuSiQue, HotpotQA, MultiFieldQA.
- Compare the performance of LLM + Retrieval for 4k & 16k/32k against non-retrieval with full context. Also, compared to GPT-3.5-turbo-16k.
Research Paper Insights:
- Open source Embedding Models/Retriever outperform OpenAI models
- The chunk size for embedding was 300 words
- The best performance of RAG was for 5-10 chunks
- Simple RAG + 4k LLM can match long context LLM.
- RAG + 32k LLM performs better than providing the full context
- RAG Llama 2 70B outperforms GPT-3.5-turbo-16k (non-RAG).
- Positional interpolation is a simple method to extend context length by ~4-8x
In this work, they systematically study the retrieval augmentation versus long context extension
using the state-of-the-art LLMs after instruction tuning for various long context QA and query-
based summarization tasks.
Summary
After the study, they have the following interesting findings:
i) Retrieval largely boosts the performance of both 4K short context LLM and 16K/32K long context LLMs.
ii) The 4K context LLMs with simple retrieval augmentation can perform comparably to 16K long
context LLMs while being more efficient at inference.
iii) After context window extension and retrieval augmentation, the best model LLaMA2-70B-32k-ret can outperform GPT-3.5-turbo-16k and Davinci003 in terms of average score on a suit of downstream tasks with informative queries.
Their study shed light on the promising direction of combining retrieval and long-context techniques together to build better LLM.
Happy Learning And Keep Learning…
Thank You…