
Hello Learners…
Welcome to my blog…
Table Of Contents
- Introduction
- What is ChatGPT?
- What Is A Large Language Model (LLM)?
- Unveiling the Secrets of ChatGPT: A Simple Explanation of Its Training Process
- Summary
- References
Introduction
In this post, we discuss the ChatGPT and we try to understand and Unveil the Secrets of ChatGPT: A Simple Explanation of Its Training Process.
If you don’t use ChatGPT even once then please visit this.
first, we try to understand what ChatGPT is.
What Is ChatGPT?
ChatGPT is an artificial intelligence (AI) chatbot developed by OpenAI and released in November 2022. The name “ChatGPT” combines “Chat“, referring to its chatbot functionality, and “GPT“, which stands for generative pre-trained transformer, a type of large language model (LLM).
ChatGPT is built upon OpenAI’s foundational GPT models, specifically GPT-3.5 and GPT-4, and has been fine-tuned (an approach to transfer learning) for conversational applications using a combination of supervised and reinforcement learning techniques.
Now, we try to understand what is a large language model (LLM).
What Is A Large Language Model (LLM)?
Large Language Models (LLMs) are very large models and are trained on a huge amount of data for solving some specific task or problem statements.
It can be text-to-text models which can be used for creating chatbots for conversation, It can be also text-to-image models which can be used for generating images from the given text.
If we talk about ChatGPT-3.5 which is trained on 175 Billion parameters, all the data is collected from the different parts of internet sources of the data.ChatGPT-4 has more parameters than ChatGPT-3.5.
Unveiling the Secrets of ChatGPT: A Simple Explanation of Its Training Process
In the process of training ChatGPT, there are mainly three stages,
- Generative Pre Training (GPT)
- Supervised Fine Tuning (SFT)
- Reinforcement Learning Through Human Feedback (RLHF)
ChatGPT is nothing but LLMs means Large language models it means that to create an LLMs we have to require a huge amount of data.

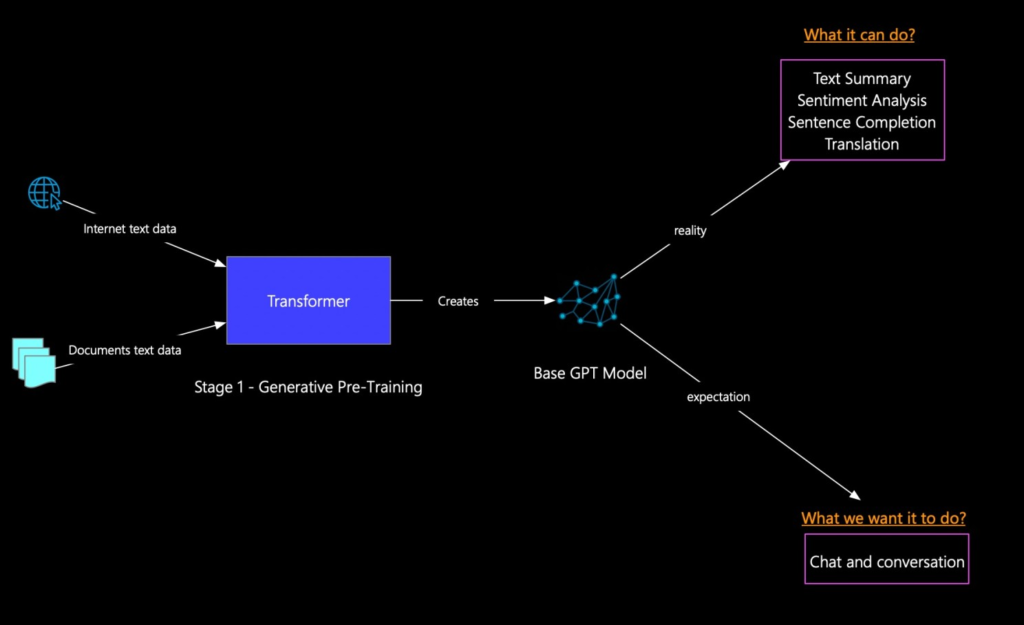
Generative Pre Training
In Generative Pre Training first, they collected a huge amount of data from the internet, books, and articles after that this data give to the Transformer architecture models which generate the BaseGPT model.
The BaseGPT model can perform some NLP(Natural Language Processing) tasks like language translation, text summarization, text completions, sentiment analysis, etc.
but when it comes to the ChatGPT it can converse like a human and give the answers to any questions in our context.
now in the second stage, they have converted the BaseGPT model to the chatbot model which can converse like humans and also save the context of the questions.
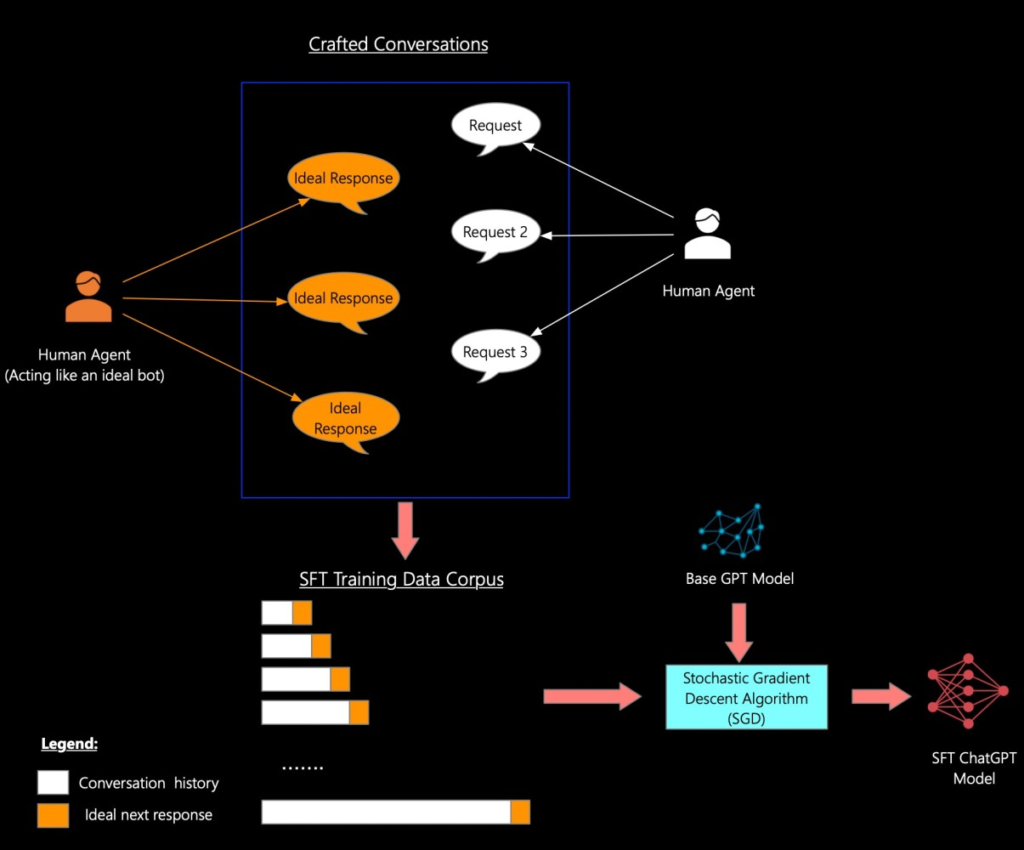
Supervised Fine Tuning (SFT)
in the second stage, a supervised fine-tuning (SFT) ChatGPT model gives a response only based on our request and response on which the ChatGPT is trained if we ask something that is not part of the request and response data and the request data is not found in the dataset which is used at the training time at that time we don’t get desired result.
To prevent this problem they use reinforcement learning through human feedback(RLHF).
Reinforcement Learning Through Human Feedback (RLHF)
In the Reinforcement Learning Through Human Feedback (RLHF) stage when Supervised Fine Tuning (SFT) gives multiple answers then there is a real human who identifies the perfect answer for the questions and based on that a real human gives a score to every answer and rank the answers based on scores. and create a reward model which gives the most ranked answers.

After that, there is one proxy model which takes the output of the reward model and the state of the conversation and based on both inputs it generates the best response for the given questions

Summary
So this is the simple understanding of the training process of the ChatGPT models.I hope you get a simple idea of how the ChatGPT is trained and how it generates the best answers to every question.