
Hello Learners…
Welcome to the blog…
Topic: Meta AI Unveils Massively Multilingual Speech (MMS) Technology
Table Of Contents
- Introduction
- Meta AI Unveils Massively Multilingual Speech (MMS) Technology
- What is Massively Multilingual Speech (MMS)?
- What Types Of Tasks Massively Multilingual Speech (MMS) Can Do?
- Summary
- References
Introduction
In this post, we discuss that recently Meta AI Unveils Massively Multilingual Speech (MMS) Technology.
Meta AI’s recently released the “Massively Multilingual Speech” (MMS) model which can transcribe 1000+ languages. It’s the first time a speech recognition model is released that can transcribe this many languages at such a high performance.
Meta AI Unveils Massively Multilingual Speech (MMS) Technology
What is Massively Multilingual Speech (MMS)?
Massively Multilingual Speech (MMS) refers to advanced technology that enables speech recognition, synthesis, and translation across a vast array of languages. It allows users to communicate and interact seamlessly with diverse individuals, regardless of language barriers. MMS systems leverage powerful artificial intelligence algorithms and language models to facilitate real-time multilingual speech processing, making it a groundbreaking advancement in the field of natural language processing.
Meta AI’s Massively Multilingual Speech (MMS) takes multi-lingual speech representations to a new level. Over 1,100 spoken languages can be identified, transcribed, and generated with the various language identification, speech recognition, and text-to-speech checkpoints released.
What Types Of Tasks Massively Multilingual Speech (MMS) Can Do?
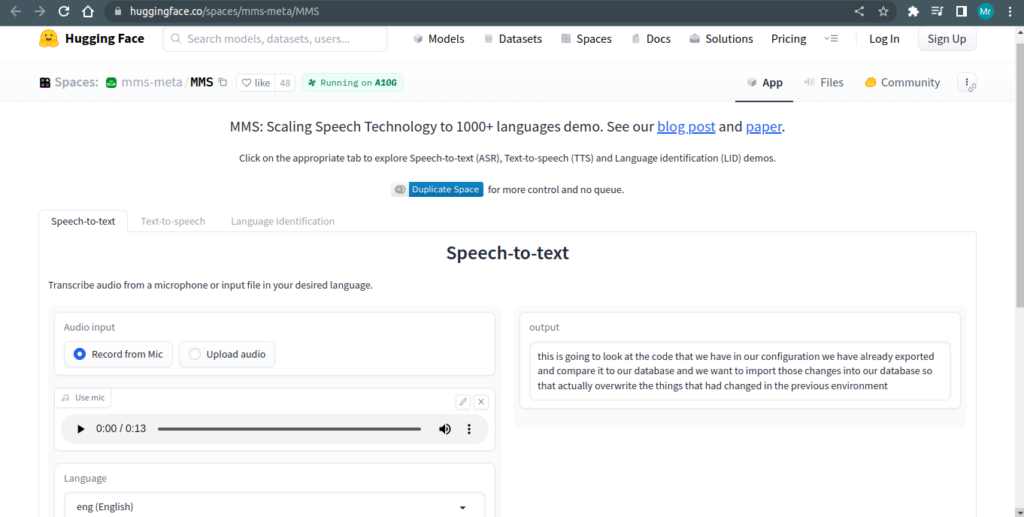
Speech To Text
Speech-to-text, also known as automatic speech recognition (ASR), is a technology that converts spoken language or audio files into written text.
It involves the process of transcribing spoken words and phrases into a written form, typically using algorithms and machine learning techniques.
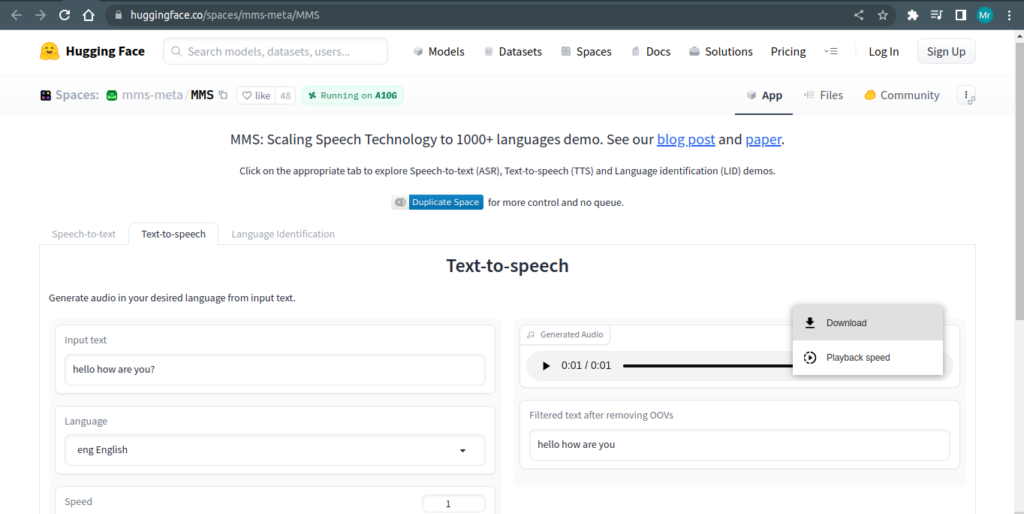
Text To Speech
Text-to-speech (TTS) is a technology that converts written text into spoken words or into audio files.
It allows computers or other devices to generate human-like speech by utilizing natural language processing and synthesis techniques.
Language Identification
Language identification, also known as language detection or language recognition, is the task of determining the language of a given text or speech input.
It involves analyzing the linguistic characteristics and patterns in the input data to identify the language in which it is written or spoken.
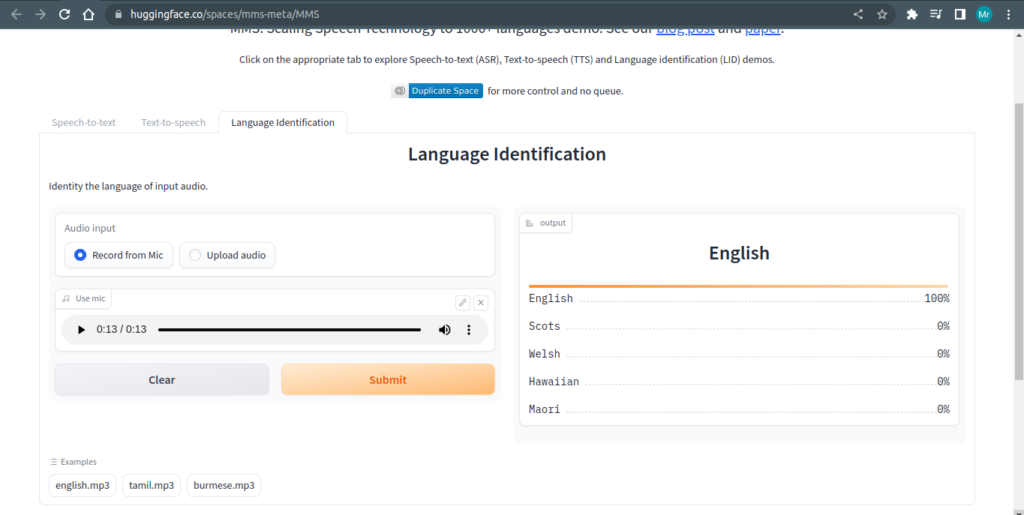
Language identification techniques continue to evolve with the advancements in natural language processing, machine learning, and acoustic analysis, enabling more accurate and efficient language detection across different modalities.
Summary
You can find the research paper below URL,
Also, Read,
Happy Learning And Keep Learning…
Thank You…